智能 AI 面试官平台 - 基于大语言模型的简历分析和模拟面试系统
InterviewGuide 是一个集成了简历分析、模拟面试(文字 + 语音)和知识库管理的智能面试辅助平台。系统利用大语言模型(LLM)、向量数据库和实时语音技术,为求职者和 HR 提供智能化的简历评估和面试练习服务。
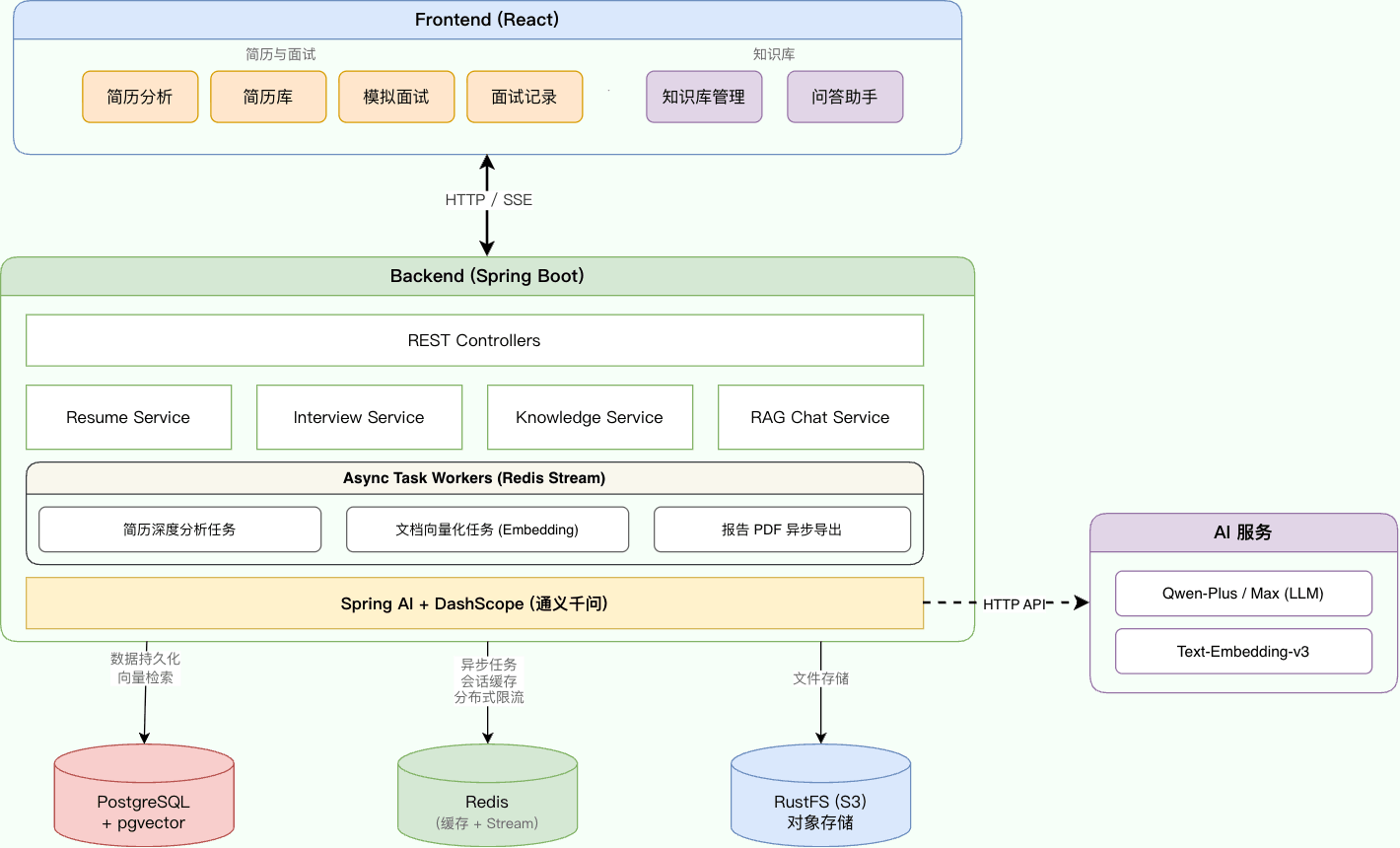
异步处理流程:
简历分析、知识库向量化和面试报告生成采用 Redis Stream 异步处理,这里以简历分析和知识库向量化为例介绍一下整体流程:
上传请求 → 保存文件 → 发送消息到 Stream → 立即返回
↓
Consumer 消费消息
↓
执行分析/向量化任务
↓
更新数据库状态
↓
前端轮询获取最新状态
状态流转: PENDING → PROCESSING → COMPLETED / FAILED。
本项目承诺完整功能免费开源,也不会做所谓的 Pro 版或“付费解锁核心功能”之类的设计。
如果你想学习这个项目,或者希望把它作为个人项目经历 / 毕设选题,我也整理了一套相对细致的教程:从基础设施搭建、核心业务实现,到最后如何在面试中讲清楚思路与亮点,尽量把容易卡住的地方讲透。
如果你确实需要更系统的辅导,可以点这里了解详情(教程为付费内容,主要是想覆盖一些时间成本,望理解,感谢支持):《SpringAI 智能面试平台+RAG 知识库》。
| 技术 | 版本 | 说明 |
|---|---|---|
| Spring Boot | 4.0.1 | 应用框架 |
| Java | 21 | 开发语言(虚拟线程) |
| Spring AI | 2.0.0-M4 | AI 集成框架 |
| PostgreSQL + pgvector | 14+ | 关系数据库 + 向量存储 |
| Redis + Redisson | 6+ / 4.0.0 | 缓存 + 消息队列(Stream) |
| Apache Tika | 2.9.2 | 文档解析 |
| iText 8 | 8.0.5 | PDF 导出 |
| MapStruct | 1.6.3 | 对象映射 |
| SpringDoc OpenAPI | 3.0.2 | API 接口文档 |
| DashScope SDK | 2.22.7 | 语音识别/合成(Qwen3 ASR/TTS) |
| WebSocket | - | 语音面试实时双向通信 |
| Gradle | 8.14 | 构建工具 |
技术选型常见问题解答:
- 数据存储为什么选择 PostgreSQL + pgvector?PG 的向量数据存储功能够用了,精简架构,不想引入太多组件。
- 为什么引入 Redis?
- Redis 替代
ConcurrentHashMap实现面试会话的缓存。 - 基于 Redis Stream 实现简历分析、知识库向量化等场景的异步(还能解耦,分析和向量化可以使用其他编程语言来做)。不使用 Kafka 这类成熟的消息队列,也是不想引入太多组件。
- Redis 替代
- 构建工具为什么选择 Gradle?个人更喜欢用 Gradle,也写过相关的文章:Gradle核心概念总结。
| 技术 | 版本 | 说明 |
|---|---|---|
| React | 18.3 | UI 框架 |
| TypeScript | 5.6 | 开发语言 |
| Vite | 5.4 | 构建工具 |
| Tailwind CSS | 4.1 | 样式框架 |
| React Router | 7.11 | 路由管理 |
| Framer Motion | 12.23 | 动画库 |
| Recharts | 3.6 | 图表库 |
| Lucide React | 0.468 | 图标库 |
| React Big Calendar | 1.19 | 面试日历组件 |
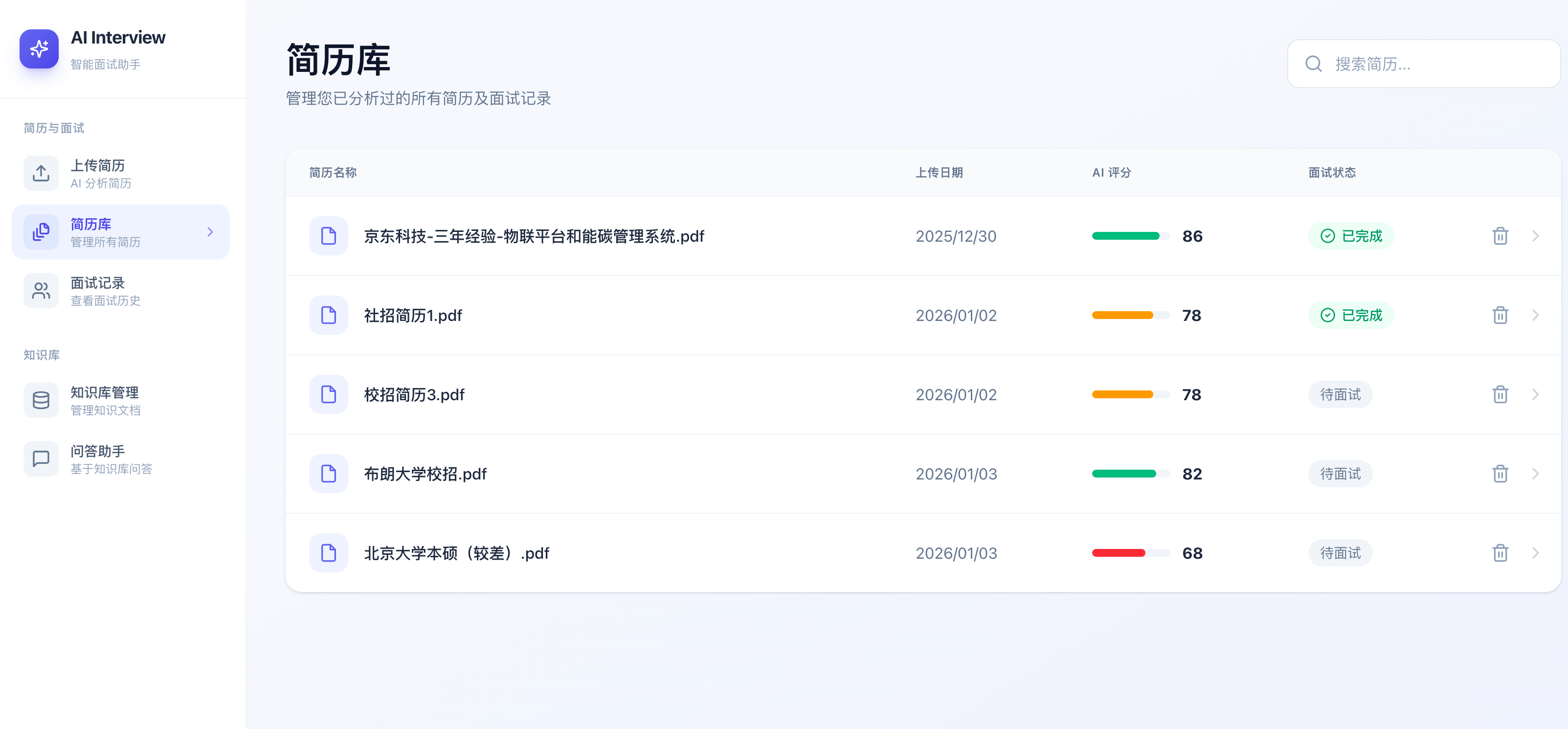
- 多格式解析:支持 PDF、DOCX、DOC、TXT 等多种简历格式。
- 异步处理流:基于 Redis Stream 实现异步简历分析,支持实时查看处理进度(待分析/分析中/已完成/失败)。
- 稳定性保障:内置分析失败自动重试机制(最多 3 次)与基于内容哈希的重复检测。
- 分析报告导出:支持将 AI 分析结果一键导出为结构化的 PDF 简历分析报告。
- Skill 驱动出题:内置 10+ 面试方向(Java 后端、阿里/字节/腾讯专项、前端、Python、算法、系统设计、测开、AI Agent 等),每个方向由
SKILL.md定义考察范围、难度分布和参考知识库。 - 历史题目去重:出题时自动排除已有会话中问过的题目,避免重复考察。
- 面试阶段时长联动:总时长滑块拖动后,各阶段(自我介绍、技术考察、项目深挖、反问环节)按时比自动分配。
- 智能追问流:支持配置多轮智能追问(默认 1 条),模拟多轮问答场景。
- 统一评估架构:文字面试和语音面试共用同一套评估引擎(分批评估 + 结构化输出 + 二次汇总 + 降级兜底),评估结果可对比。
- 报告一键导出:支持异步生成并导出详细的 PDF 模拟面试评估报告。
- 面试中心入口:面试中心页整合文字面试和语音面试入口,支持继续面试和重新面试。
智能面试日程管理,支持自动解析面试邀请:
-
智能邀请解析:
- 规则解析:支持飞书、腾讯会议、Zoom 等主流会议平台格式
- AI 解析:复杂文本自动提取公司、岗位、时间、会议链接等信息
- 自动识别面试形式(现场/视频/电话)和轮次
-
日历视图管理:
- 多视图切换:日/周/月视图,灵活查看面试安排
- 拖拽调整:支持拖拽面试卡片快速调整时间
- 列表视图:提供简洁的列表展示方式
-
状态自动更新:
- 定时任务自动更新过期面试状态
- 手动标记面试状态(待面试/已完成/已取消)
-
集成提醒:支持配置面试提醒,避免错过重要面试
实时语音对话面试,基于 WebSocket 双向通信 + 千问3语音模型:
-
ASR (语音识别): qwen3-asr-flash-realtime
- 实时流式识别,服务端 VAD(Voice Activity Detection)
- 400ms 断句延迟(比传统方案快 50%)
- 准确率提升 5%+,达到 ~95%+
-
TTS (语音合成): qwen3-tts-flash-realtime
- Cherry 音色(温柔女声)
- 流式合成,中文优化
- 首包延迟 200ms(快 60%)
-
核心特性:
- LLM 流式输出 + 句子级并发 TTS:AI 回复边生成边合成语音,首句音频可以更快推送到前端
- 分块音频推送:TTS 合成的音频按句分块实时推送到前端,实现"边说边播"
- 实时字幕显示(支持中间结果)
- 自动断句检测(基于服务端 VAD)
- 手动提交模式 + 回声防护:用户主动点击提交答案,避免 AI 语音被误录入
- 多轮对话管理(上下文记忆)
- 会话暂停/恢复(超时自动暂停)
- 多种开场话术(不同面试方向对应不同开场白)
- 统一 API Key(LLM + ASR + TTS 共用一个密钥)
- Micrometer 指标埋点(TTS/ASR 延迟、会话时长等)
已知体验问题
- 端到端延迟偏高:当前方案是 ASR → 文本 → LLM → 文本 → TTS → 音频,音频需经服务端中转,弱网环境下延迟感知明显。
- 回声泄漏:虽有回声防护,但在无耳机场景下,AI 语音仍可能被麦克风拾取导致误识别。
- TTS 音色单一:目前仅支持 Cherry 一种音色,用户无法选择面试官风格。
- 弱网音频断续:流式 TTS 在高丢包率环境下可能出现播放卡顿。
后续改进方向
- 探索 WebRTC 替代 WebSocket,减少音频中转延迟
- 引入客户端 VAD + 降噪预处理,降低嘈杂环境下的误识别
- 支持更多 TTS 音色和语速调节
- 接入端到端语音模型(如 OpenAI Realtime API),省去 ASR→LLM→TTS 的串行管道
- 音频缓冲策略优化,弱网环境下平滑播放
- 文档智能处理:支持 PDF、DOCX、Markdown 等多种格式文档的自动上传、分块与异步向量化。
- RAG 检索增强:集成向量数据库,通过检索增强生成(RAG)提升 AI 问答的准确性与专业度。
- 流式响应交互:基于 SSE(Server-Sent Events)技术实现打字机式流式响应。
- 智能问答对话:支持基于知识库内容的智能问答,并提供直观的知识库统计信息。
- 问答助手的 Markdown 展示优化
- 知识库管理页面的知识库下载
- 异步生成模拟面试评估报告
- Docker 快速部署
- 添加 API 限流保护
- 前端性能优化(RAG 聊天 - 虚拟列表)
- 模拟面试增加追问功能
- 语音面试功能(基于 Qwen3 实时语音模型)
- 面试安排管理(智能解析 + 日历视图)
- Skill 驱动出题(10+ 面试方向 + 参考知识库)
- 统一面试评估架构(文字/语音共用评估引擎)
- 面试历史题目去重
- 面试中心页(整合文字/语音入口)
- 语音面试 LLM 流式输出 + 句子级并发 TTS
- 语音面试暂停/恢复 + 手动提交 + 回声防护
- 打通模拟面试和知识库
- 语音面试接入 WebRTC 降低延迟
- 语音面试支持更多 TTS 音色
- 多 LLM Provider 路由与动态切换
简历库:
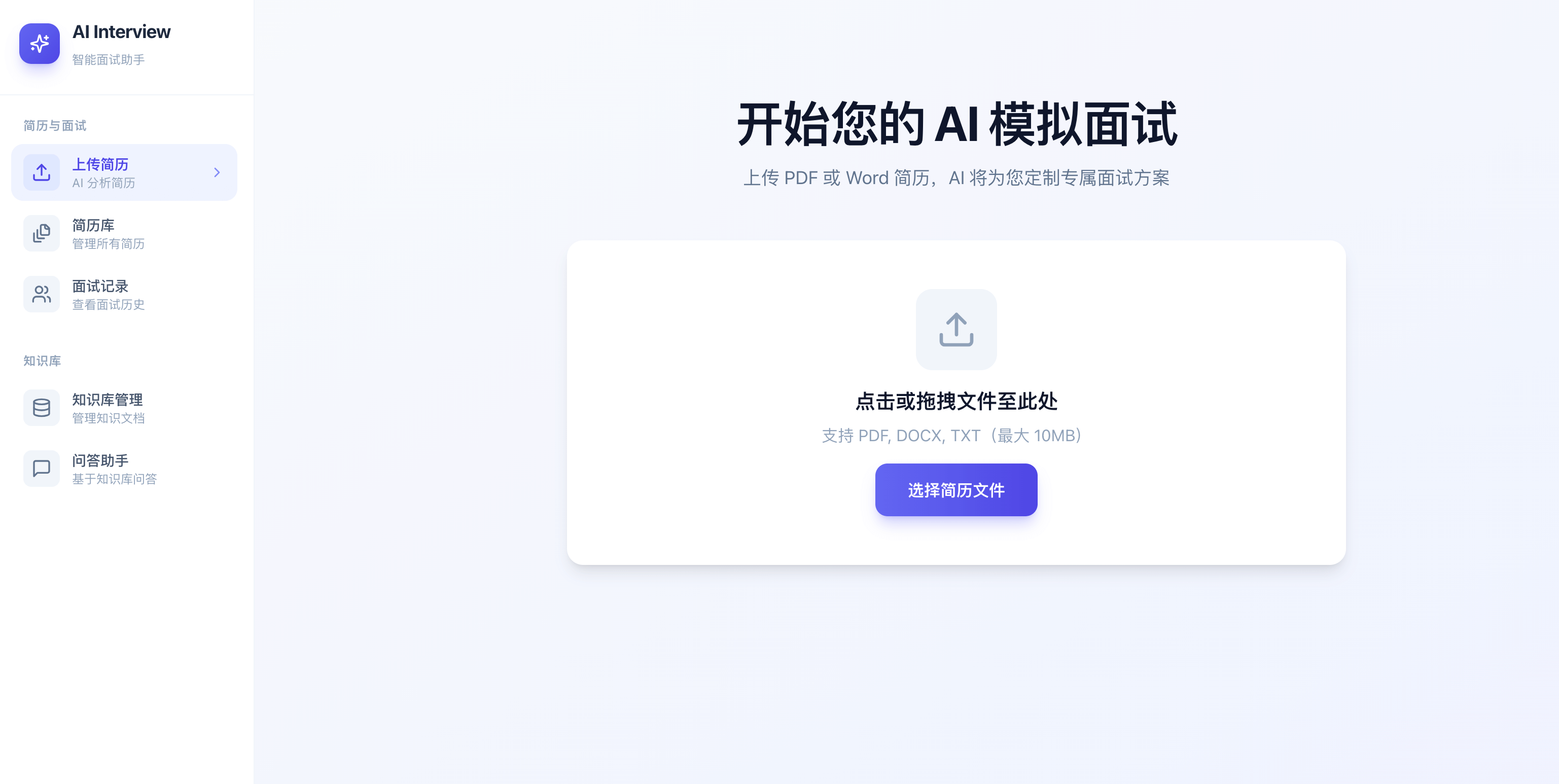
简历上传分析:
简历分析详情:

面试记录:
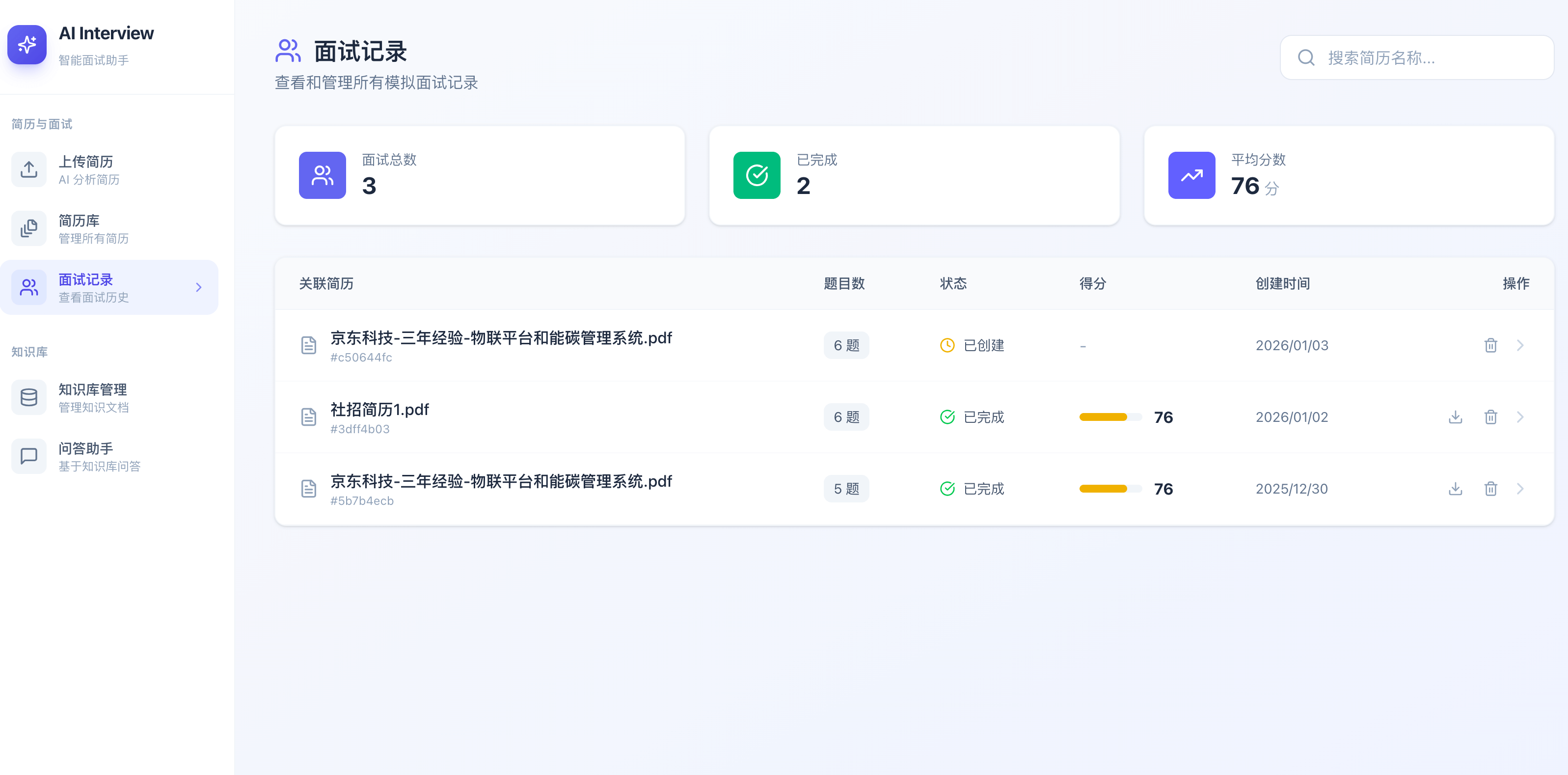
面试详情:
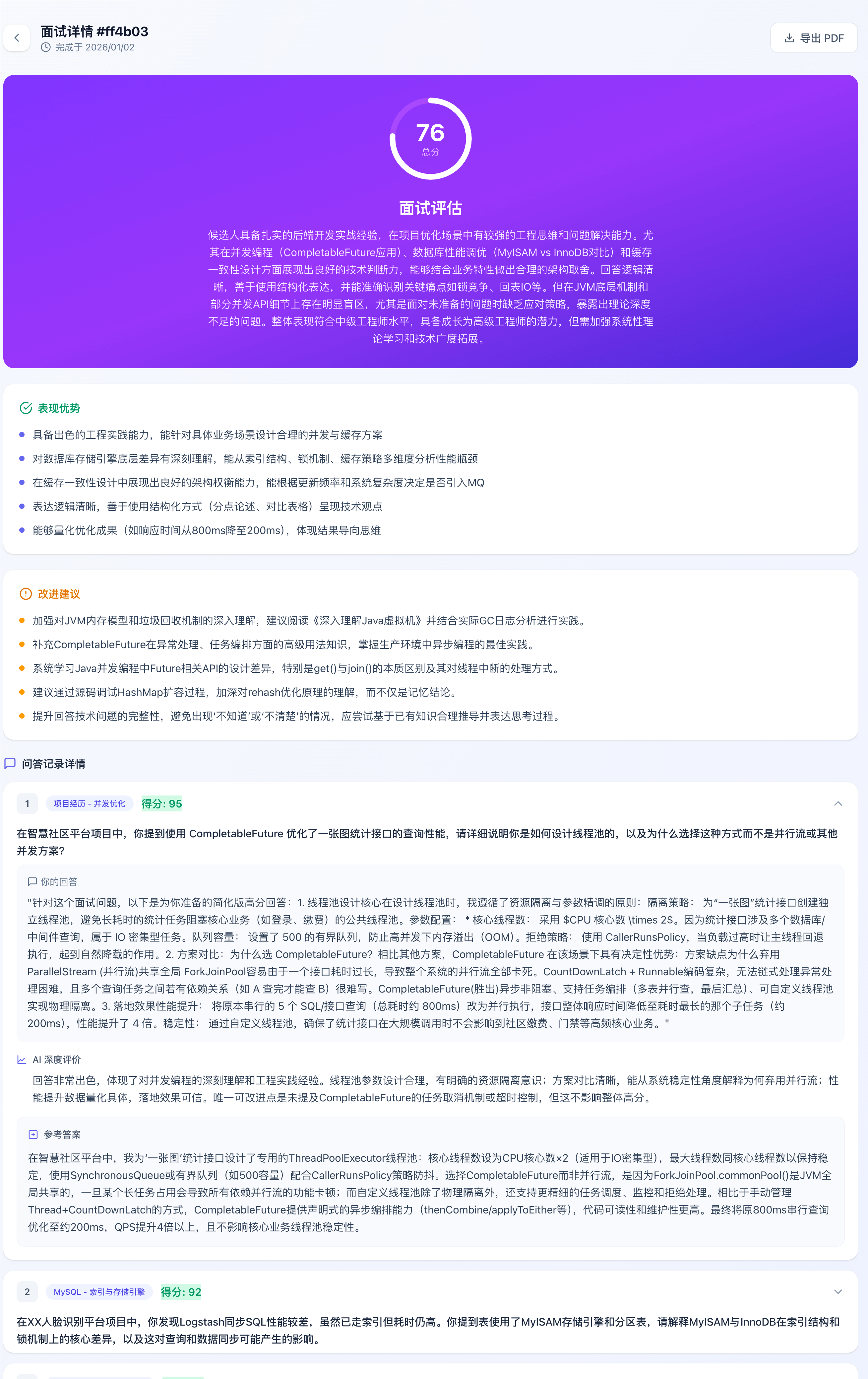
模拟面试:
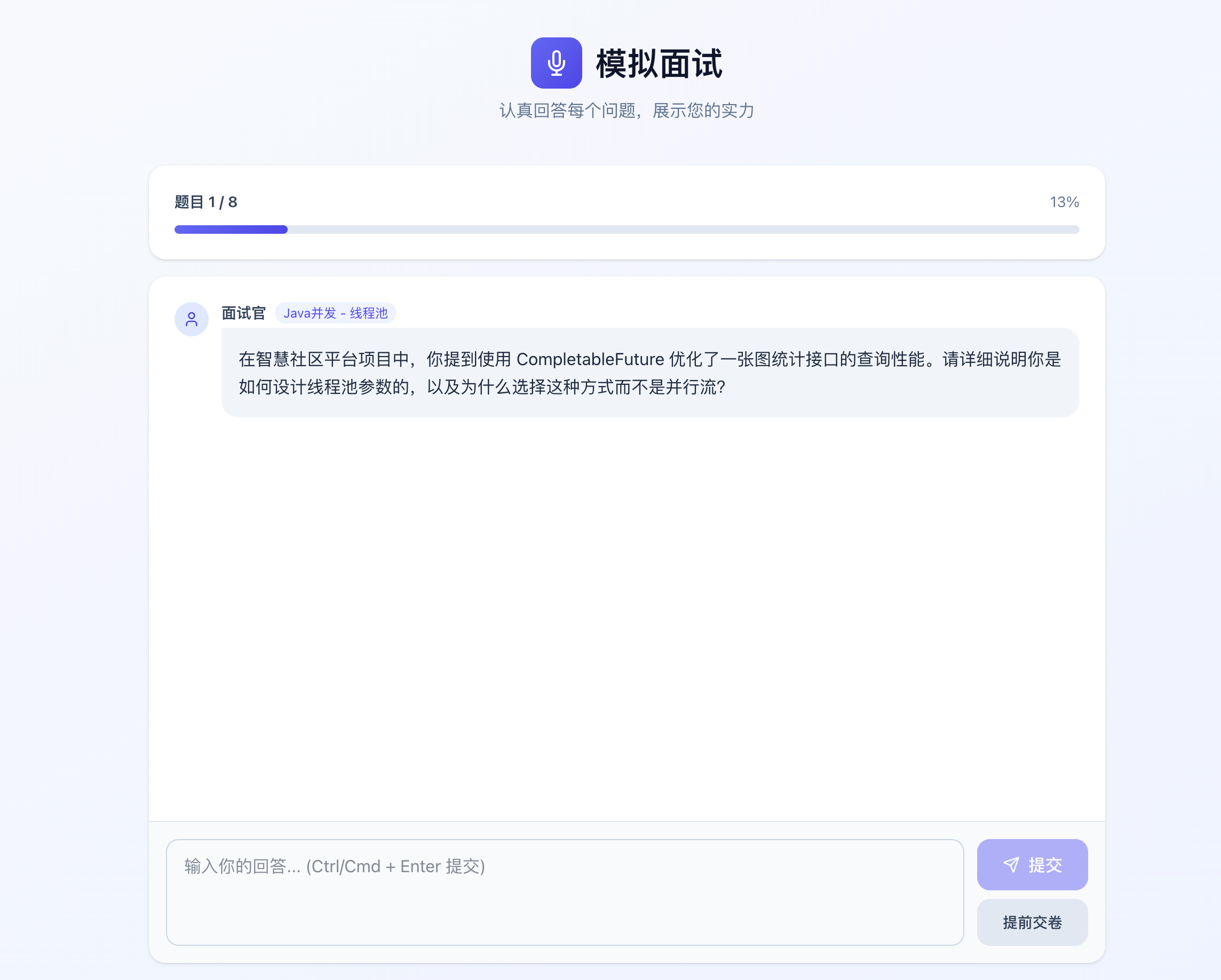
面试安排(日历视图):

面试安排(列表视图):

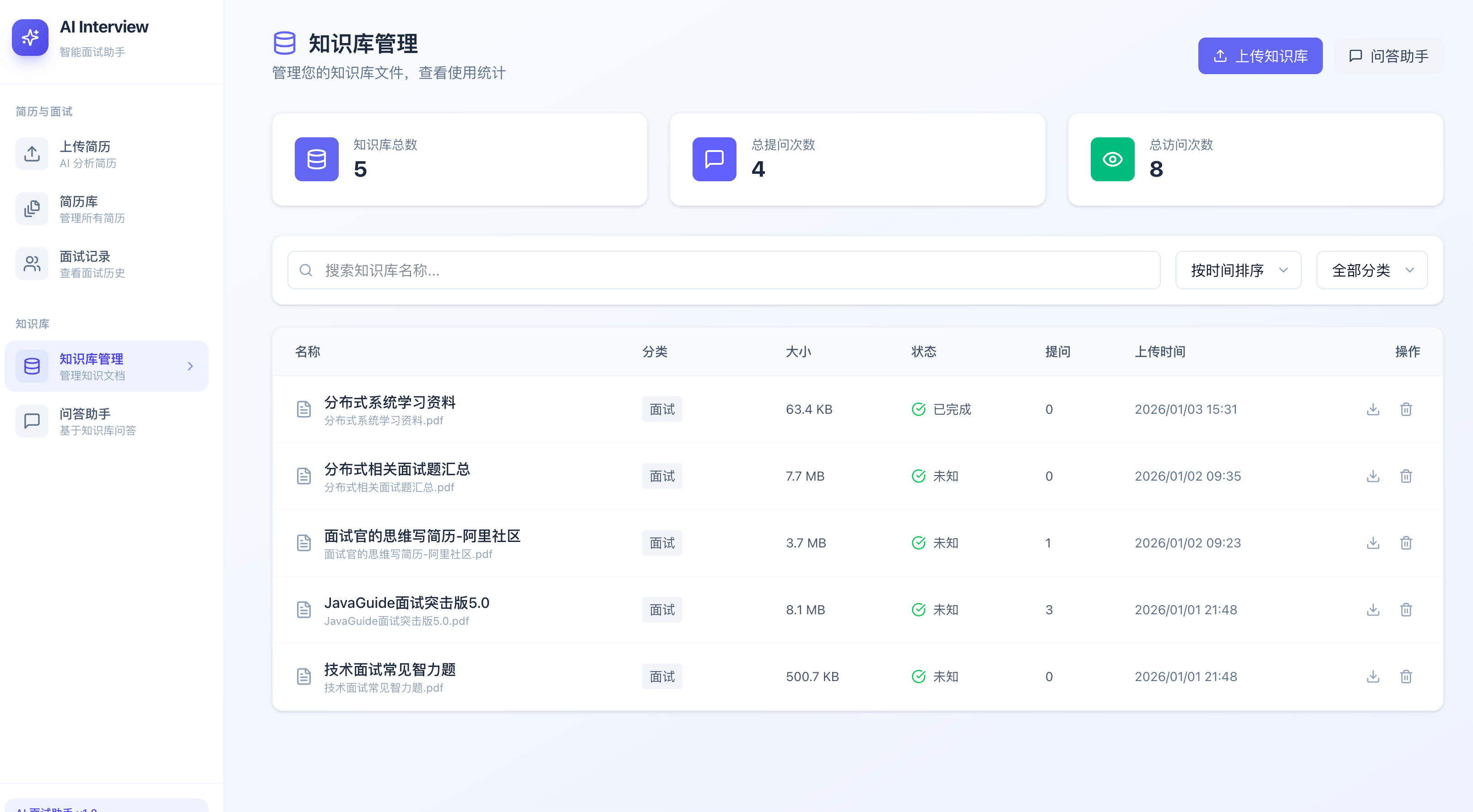
知识库管理:
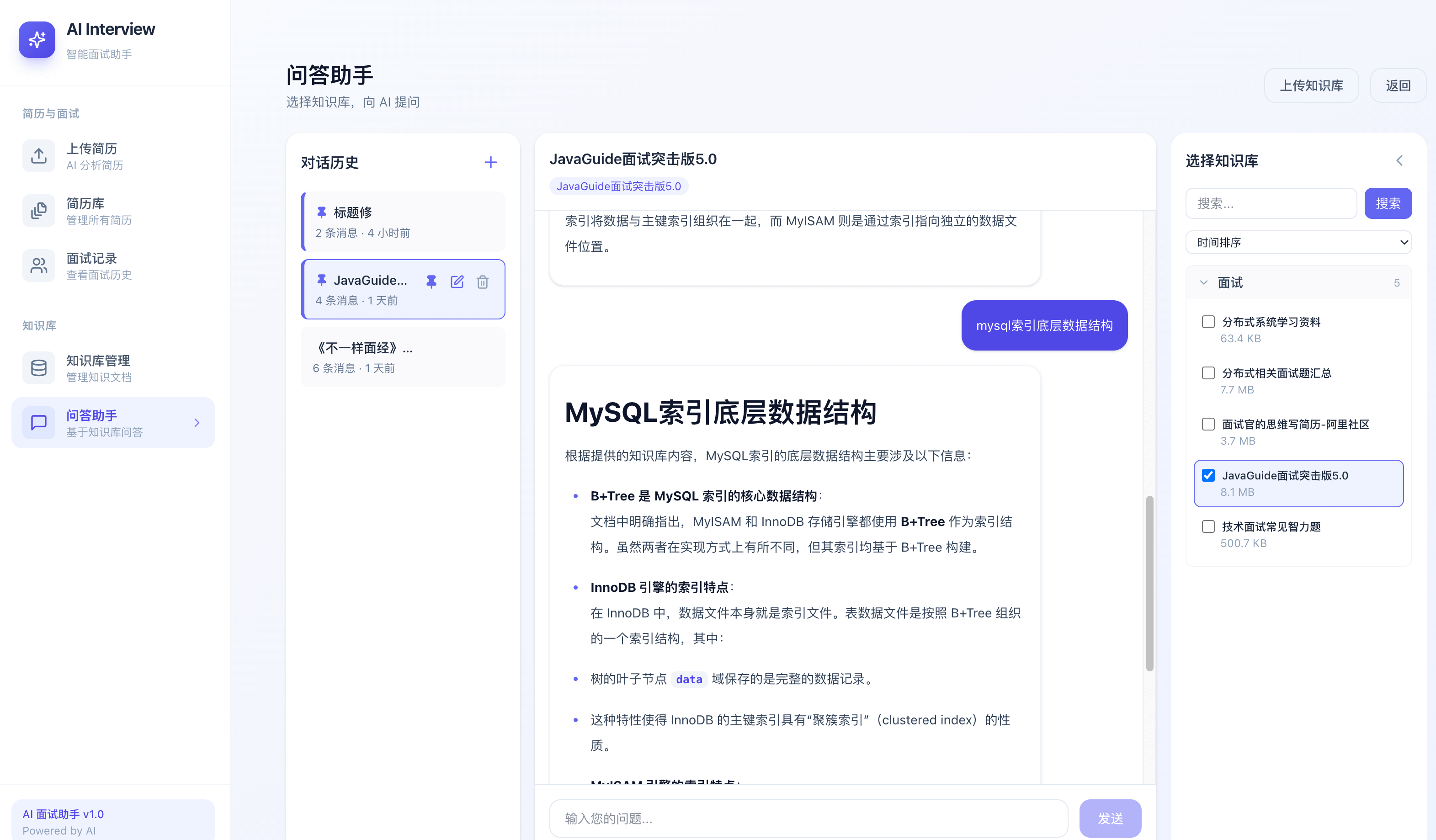
问答助手:
interview-guide/
├── app/ # 后端应用
│ ├── src/main/java/interview/guide/
│ │ ├── App.java # 主启动类
│ │ ├── common/ # 通用模块
│ │ │ ├── config/ # 配置类
│ │ │ ├── exception/ # 异常处理
│ │ │ └── result/ # 统一响应
│ │ ├── infrastructure/ # 基础设施
│ │ │ ├── export/ # PDF 导出
│ │ │ ├── file/ # 文件处理
│ │ │ ├── redis/ # Redis 服务
│ │ │ └── storage/ # 对象存储
│ │ └── modules/ # 业务模块
│ │ ├── interview/ # 模拟面试模块
│ │ ├── interviewschedule/ # 面试安排模块
│ │ ├── voiceinterview/ # 语音面试模块
│ │ ├── knowledgebase/ # 知识库模块
│ │ └── resume/ # 简历模块
│ └── src/main/resources/
│ ├── application.yml # 应用配置
│ └── prompts/ # AI 提示词模板
│
├── frontend/ # 前端应用
│ ├── src/
│ │ ├── api/ # API 接口
│ │ ├── components/ # 公共组件
│ │ ├── pages/ # 页面组件
│ │ ├── types/ # 类型定义
│ │ └── utils/ # 工具函数
│ ├── package.json
│ └── vite.config.ts
│
└── README.md
环境要求:
| 依赖 | 版本 | 必需 |
|---|---|---|
| JDK | 21+ | 是 |
| Node.js | 18+ | 是 |
| PostgreSQL | 14+ | 是 |
| pgvector 扩展 | - | 是 |
| Redis | 6+ | 是 |
| S3 兼容存储 | - | 是 |
git clone https://github.com/Snailclimb/interview-guide.git
cd interview-guide-- 创建数据库
CREATE DATABASE interview_guide;
-- 连接数据库并启用 pgvector 扩展(可选,启动后端SpringAI框架底层会自动创建)
CREATE EXTENSION vector;# AI API 密钥(阿里云 DashScope)
export AI_BAILIAN_API_KEY=your_api_key编辑 app/src/main/resources/application.yml:
spring:
# PostgreSQL数据库配置
datasource:
url: jdbc:postgresql://${POSTGRES_HOST:localhost}:${POSTGRES_PORT:5432}/${POSTGRES_DB:interview_guide}
username: ${POSTGRES_USER:postgres}
password: ${POSTGRES_PASSWORD:password}
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: update # 首次启动自动创建表,后续保留数据并增量更新
# Redisson配置 (使用 spring.redis.redisson,参考官方文档)
redis:
redisson:
config: |
singleServerConfig:
address: "redis://${REDIS_HOST:localhost}:${REDIS_PORT:6379}"
database: 0
connectionMinimumIdleSize: 10
connectionPoolSize: 64
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
# RustFS (S3兼容) 存储配置
app:
# 面试配置
interview:
follow-up-count: ${APP_INTERVIEW_FOLLOW_UP_COUNT:1} # 每个主问题生成追问数量
evaluation:
batch-size: ${APP_INTERVIEW_EVALUATION_BATCH_SIZE:8} # 回答评估分批大小
storage:
endpoint: ${APP_STORAGE_ENDPOINT:http://localhost:9000}
access-key: ${APP_STORAGE_ACCESS_KEY:minioadmin}
secret-key: ${APP_STORAGE_SECRET_KEY:minioadmin}
bucket: ${APP_STORAGE_BUCKET:interview-guide}
region: ${APP_STORAGE_REGION:us-east-1}
- JPA 的
ddl-auto已配置为update(智能模式),首次启动会自动创建表,后续重启保留数据。 - 如果本地有 Minio 的话,可以用其替换 RustFS。
若使用本仓库的 Docker 只启动依赖(PostgreSQL / Redis / MinIO),可先执行 docker compose up -d postgres redis minio createbuckets,将根目录 .env.example 复制为 .env 并填写 AI_BAILIAN_API_KEY,再运行后端;默认账号与 docker-compose.yml 一致。需要显式启用 application-dev.yml 时,可使用 ./gradlew bootRun --args='--spring.profiles.active=dev'。
后端:
./gradlew bootRun后端服务启动于 http://localhost:8080
前端:
cd frontend
pnpm install
pnpm dev前端服务启动于 http://localhost:5173
本项目提供了完整的 Docker 支持,可以一键启动所有服务(前后端、数据库、中间件)。
- 安装 Docker 和 Docker Compose
- 申请阿里云百炼 API Key(用于 AI 对话功能)
在项目根目录下执行:
.env.example 中的 PostgreSQL、Redis、MinIO 已与 docker-compose.yml 对齐(数据库用户 postgres / 密码 password,MinIO minioadmin / minioadmin)。复制为 .env 后主要填写 AI_BAILIAN_API_KEY;若你曾在旧版本中使用过不同的库密码或对象存储密钥,请同步修改 .env,必要时重建 Postgres 卷以免旧数据与密码不一致。
# 1. 复制环境变量配置文件
cp .env.example .env
# 2. 编辑 .env 文件,填入 AI 配置
# vim .env
# 必填:AI_BAILIAN_API_KEY=your_key_here
# 可选:AI_MODEL=qwen-plus # 默认值为 qwen-plus
# # 也可以改为 qwen-max、qwen-long 等其他可用模型
#
# 多 LLM 提供商支持(可选):
# APP_VOICE_INTERVIEW_LLM_PROVIDER=dashscope # 默认使用 DashScope
# # 也支持:minimax, openai, deepseek, lmstudio
# # 如需使用其他提供商,请参考 .env.example 中的配置说明
#
# 面试参数配置(可选):
# APP_INTERVIEW_FOLLOW_UP_COUNT=1 # 每个主问题生成追问数量(默认 1)
# APP_INTERVIEW_EVALUATION_BATCH_SIZE=8 # 回答评估分批大小(默认 8)
# 3. 构建并启动所有服务
docker-compose up -d --build启动完成后,您可以通过以下地址访问各个服务:
| 服务 | 地址 | 默认账号 | 默认密码 | 说明 |
|---|---|---|---|---|
| 前端应用 | http://localhost | - | - | 用户访问入口 |
| 后端 API | http://localhost:8080 | - | - | RESTful API |
| 接口文档 | http://localhost:8080/swagger-ui.html | - | - | SpringDoc/Swagger UI |
| MinIO 控制台 | http://localhost:9001 | minioadmin |
minioadmin |
对象存储管理 |
| MinIO API | localhost:9000 |
- | - | S3 兼容接口 |
| PostgreSQL | localhost:5432 |
postgres |
password |
数据库 (包含 pgvector) |
| Redis | localhost:6379 |
- | - | 缓存与消息队列 |
# 查看服务状态
docker-compose ps
# 查看后端日志
docker-compose logs -f app
# 停止并移除所有服务
docker-compose down
# 清理无用镜像(构建产生的中间层)
docker image prune -f| 用户角色 | 使用场景 |
|---|---|
| 求职者 | 上传简历获取分析建议,进行模拟面试练习 |
| HR/招聘人员 | 批量分析简历,评估候选人能力 |
| 培训机构 | 提供面试培训服务,管理知识库资源 |
检查 JPA 的 ddl-auto 配置。ddl-auto 模式对比:
| 模式 | 行为 | 适用场景 | 数据保留 |
|---|---|---|---|
| update | 智能模式:表不存在自动创建,存在则增量更新 | 开发环境(推荐) | ✅ 保留 |
| create | 无条件删除并重建所有表 | 仅首次建表时使用 | ❌ 删除 |
| validate | 只验证,不修改 | 生产环境 | ✅ 保留 |
| none | 什么都不做 | 生产环境 | ✅ 保留 |
推荐配置(已默认):
jpa:
hibernate:
ddl-auto: update # 首次启动自动创建表,后续保留数据并增量更新create 模式,否则每次重启都会删除所有数据!
当 initialize-schema: false 时,Spring AI 不会自动创建 vector_store 表。
spring:
ai:
vectorstore:
pgvector:
initialize-schema: true 建议开发环境设置为 true,方便快速启动。生产环境设置为 false,手动管理数据库 schema,避免意外变更。
检查一下阿里云 DashScope API KEY 是否配置正确(申请地址:https://bailian.console.aliyun.com/)。
检查 Redis 连接和 Stream Consumer 是否正常运行。查看后端日志确认是否有错误。
项目已内置中文字体(珠圆玉润仿宋),支持跨平台导出。如遇到问题,请检查:
- 字体文件是否存在:
app/src/main/resources/fonts/ZhuqueFangsong-Regular.ttf - 检查日志中的字体加载信息
- 确认 iText 依赖是否正确
原因简述:后端与 Logback 按 UTF-8 输出日志;中文 Windows 下控制台默认多为 GBK(代码页 936),且 PowerShell 的 $OutputEncoding、控制台编码若未统一为 UTF-8,显示时就会把同一串字节解释错,出现乱码。
本项目已做的配置(一般无需再改):根目录 gradle.properties(Gradle 进程 UTF-8)、app/src/main/resources/logback-spring.xml(控制台日志 UTF-8)、app/build.gradle 中 bootRun 的 JVM 参数(含 file.encoding / stdout.encoding / stderr.encoding)。
仍乱码时(PowerShell 侧):在启动 ./gradlew bootRun 的同一终端先执行下面一段;或写入 PowerShell 配置文件($PROFILE)以便每次自动生效:
chcp 65001 | Out-Null
[Console]::OutputEncoding = [System.Text.UTF8Encoding]::new($false)
[Console]::InputEncoding = [System.Text.UTF8Encoding]::new($false)
$OutputEncoding = [System.Text.UTF8Encoding]::new($false)新建或编辑配置文件:if (!(Test-Path $PROFILE)) { New-Item -Path $PROFILE -ItemType File -Force },再 notepad $PROFILE 将上述内容粘贴保存;新开终端后生效,或执行 . $PROFILE 立即加载。若提示脚本无法执行,可执行一次:Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy RemoteSigned。
在 PowerShell 中建议使用 .\gradlew.bat :app:bootRun(或仓库根目录的 .\gradlew.bat),避免与执行策略、路径解析相关的问题。
欢迎提交 Issue 和 Pull Request!
AGPL-3.0 License(只要通过网络提供服务,就必须向用户公开修改后的源码)