A curated, experiment-driven collection of foundational and modern Reinforcement Learning (RL) algorithms implemented from scratch in PyTorch and NumPy, benchmarked across classic control and discrete environments.
This repository aggregates implementations spanning value-based, policy-gradient, and deterministic continuous-control paradigms:
Algorithms included:
- Tabular: Q-Learning, SARSA
- Value-Based Deep RL: DQN, Double DQN (DDQN)
- Policy Gradient / Stochastic Actor–Critic: Vanilla Actor-Critic, Advantage Actor-Critic (A2C), Proximal Policy Optimization (PPO)
- Deterministic Actor–Critic for Continuous Control: DDPG, Twin Delayed DDPG (TD3)
Environments used (Gymnasium): FrozenLake-v1, Taxi-v3, CartPole-v1, Pendulum-v1, BipedalWalker-v3 (fallback to Pendulum if Box2D unavailable).
Below are the core update rules and objectives distinguishing the algorithms.
- Q-Learning (off-policy, bootstrapped):

- SARSA (on-policy):
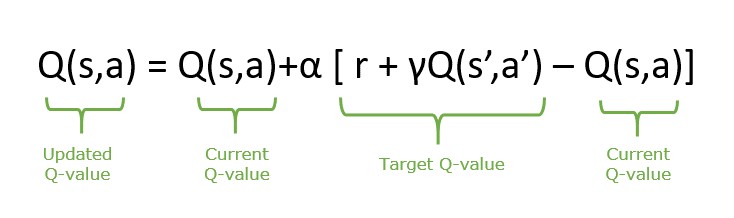
- DQN:

- Double DQN:
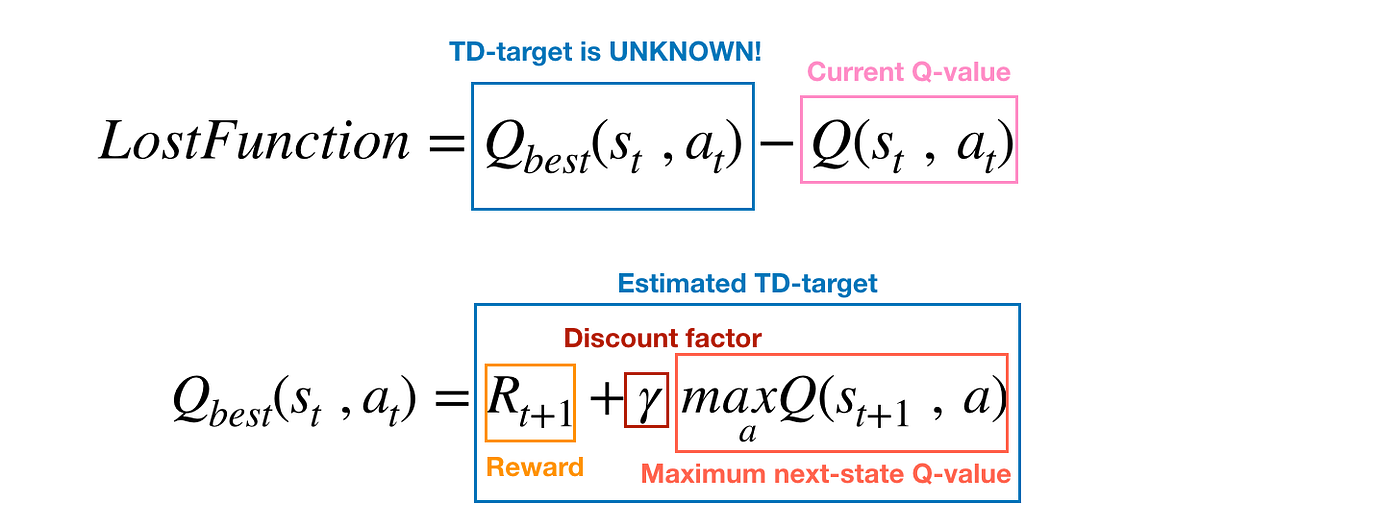
- Policy Objective:
- REINFORCE Gradient:
- Actor–Critic Advantage:
- Actor Loss & Critic Loss:
- A2C (synchronous multi-step return):
- Probability Ratio:
- Clipped Surrogate Objective:
- Deterministic Policy:
- Critic Target:
- Actor Gradient:
-
TD3 Enhancements:
- Twin Critics: take minimum to mitigate overestimation bias
$$ Q_{\text{target}} = \min(Q_1, Q_2) $$
- Target Policy Smoothing: add clipped noise to target actions
$$ a'_{\text{target}} = \mu_{\theta'}(s') + \text{clip}(\epsilon, -c, c), \quad \epsilon \sim \mathcal{N}(0, \sigma^2) $$
- Delayed Policy Updates: update actor less frequently than critic
| Algorithm | Paradigm | Strengths | Limitations | When to Use |
|---|---|---|---|---|
| Q-Learning | Tabular Off-Policy | Simple, convergence guarantees in finite MDPs | Not scalable to large/continuous spaces | Small discrete state spaces |
| SARSA | Tabular On-Policy | Safer (accounts for exploration policy) | Can under-explore optimal risky paths | When conservative estimates preferred |
| DQN | Value-Based Deep | Scales to large state spaces; replay + target stabilize | Overestimation bias | Discrete high-dimensional observations |
| Double DQN | Value-Based Deep | Reduces overestimation | Slightly more compute (two forward passes) | Stable discrete action problems |
| Actor-Critic (Vanilla) | Policy Gradient + Value Baseline | Lower variance than pure REINFORCE | High variance advantage estimates | Educational baselines |
| A2C | Synchronous Advantage Actor-Critic | Multi-step returns improve bias/variance tradeoff | Less sample efficient than PPO | Fast prototyping on small tasks |
| PPO | Trust-Region Inspired | Stable updates, robust to hyperparameters | More computation (multiple epochs) | General-purpose baseline |
| DDPG | Deterministic Continuous Control | Handles continuous actions | Sensitive to noise & hyperparameters | Simpler continuous tasks |
| TD3 | Improved DDPG | Mitigates Q overestimation; more stable | More components to tune | Continuous control with noisy rewards |
python -m venv .venv
source .venv/bin/activate
pip install torch gymnasium[box2d] matplotlib numpy imageio(Optional) macOS prerequisites for Box2D: brew install swig then reinstall gymnasium extras.
Q-Learning’s maximization introduces optimistic estimates aiding faster exploitation; SARSA’s on-policy target incorporates exploratory actions leading to safer convergence in stochastic settings.

|

|
Double DQN reduces positive bias by decoupling action selection and evaluation—improving stability and preventing premature saturation of Q-values.

|

|
Vanilla Actor-Critic suffers from high variance; A2C’s synchronous n-step returns lower variance while retaining a tractable bias–variance tradeoff. PPO’s clipped surrogate prevents destructive policy updates (implicit trust region) increasing reproducibility.

|

|
DDPG is sensitive to noise and overestimation; TD3 addresses these via critic redundancy, target smoothing (regularization of sharp Q surfaces), and delayed policy updates (reducing actor drift).

|

|